关于我
叶金荣(yejr)早年曾混迹于linuxforum、linuxsir、chinaunix等社区。
2006年建本站至今,是国内最早的一批MySQL技术博客之一。
从事过LAMP开发,后成为专职MySQL DBA,擅长MySQL优化、数据库架构设计及对比基准压测。
2012年被提名成为ORACLE MySQL ACE。
2015年创办靠谱、优质的在线培训品牌知数堂专注培养优秀互联网从业人才以及企业服务。
2018年发起「3306π」社区
微信公众号:老叶茶馆(imysql_wx)
微博:@叶金荣
QQ群: 579036588
邮箱:yejr@qq.com
神器: 自动生成my.cnf
买茶找我: 自家茶叶店
【老叶茶馆】微信公众号二维码
热门内容
最近评论
- 在NDB Cluster集群中 11 年 9 months 前
- 会占用的,除非该连接被释放掉。 11 年 9 months 前
- 参见选项:--replicate-do-table 11 年 9 months 前
- ICP是5.6新出来的东西,从历史经验来看肯定还不够完善 11 年 9 months 前
- 1、需要重启; 2、单位可以写成 G 的; 11 年 9 months 前
- 最新的5.6版本下,已经可以不用这么做了。修改完配置文件后 11 年 9 months 前
- 官方5.6版本的并行复制是 database 级的并行 11 年 9 months 前
- 可以关注下我以往的一个分享:http://wenku 11 年 9 months 前
- NoOfReplicas 11 年 9 months 前
- 是的,今天我也要传输572G文件,跨IDC但有落纤(不限速 11 年 9 months 前
MySQL Cluster(MySQL 集群) 初试
MySQL Cluster 是MySQL适合于分布式计算环境的高实用、高冗余版本。它采用了NDB Cluster 存储引擎,允许在1个 Cluster 中运行多个MySQL服务器。在MyQL 5.0及以上的二进制版本中、以及与最新的Linux版本兼容的RPM中提供了该存储引擎。(注意,要想获得MySQL Cluster 的功能,必须安装 mysql-server 和 mysql-max RPM)。
目前能够运行MySQL Cluster 的操作系统有Linux、Mac OS X和Solaris(一些用户通报成功地在FreeBSD上运行了MySQL Cluster ,但MySQL AB公司尚未正式支持该特性)。
一、MySQL Cluster概述
MySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的 Cluster 。通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,由于每个组件有自己的内存和磁盘,不存在单点故障。
MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster 的数据节点,管理服务器,以及(可能)专门的数据访问程序。关于 Cluster 中这些组件的关系,请参见下图: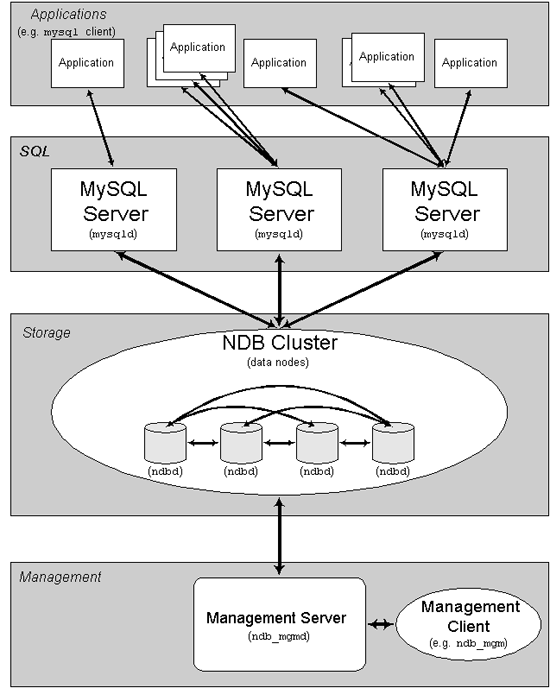
所有的这些节点构成一个完成的MySQL集群体系。数据保存在“NDB存储服务器”的存储引擎中,表(结构)则保存在“MySQL服务器”中。应用程序通过“MySQL服务器”访问这些数据表,集群管理服务器通过管理工具(ndb_mgmd)来管理“NDB存储服务器”。
通过将MySQL Cluster 引入开放源码世界,MySQL为所有需要它的人员提供了具有高可用性、高性能和可缩放性的 Cluster 数据管理。
二、MySQL Cluster 基本概念
“NDB” 是一种“内存中”的存储引擎,它具有可用性高和数据一致性好的特点。
MySQL Cluster 能够使用多种故障切换和负载平衡选项配置NDB存储引擎,但在 Cluster 级别上的存储引擎上做这个最简单。MySQL Cluster的NDB存储引擎包含完整的数据集,仅取决于 Cluster本身内的其他数据。
目前,MySQL Cluster的 Cluster部分可独立于MySQL服务器进行配置。在MySQL Cluster中, Cluster的每个部分被视为1个节点。
- 管理(MGM)节点:这类节点的作用是管理MySQL Cluster内的其他节点,如提供配置数据、启动并停止节点、运行备份等。由于这类节点负责管理其他节点的配置,应在启动其他节点之前首先启动这类节点。MGM节点是用命令“ndb_mgmd”启动的。
- 数据节点:这类节点用于保存 Cluster的数据。数据节点的数目与副本的数目相关,是片段的倍数。例如,对于两个副本,每个副本有两个片段,那么就有4个数据节点。不过没有必要设置多个副本。数据节点是用命令“ndbd”启动的。
- SQL节点:这是用来访问 Cluster数据的节点。对于MySQL Cluster,客户端节点是使用NDB Cluster存储引擎的传统MySQL服务器。通常,SQL节点是使用命令“mysqld –ndbcluster”启动的,或将“ndbcluster”添加到“my.cnf”后使用“mysqld”启动。
注释:在很多情况下,术语“节点”用于指计算机,但在讨论MySQL Cluster时,它表示的是进程。在单台计算机上可以有任意数目的节点,为此,我们采用术语“ Cluster主机”。
管理服务器(MGM节点)负责管理 Cluster配置文件和 Cluster日志。 Cluster中的每个节点从管理服务器检索配置数据,并请求确定管理服务器所在位置的方式。当数据节点内出现新的事件时,节点将关于这类事件的信息传输到管理服务器,然后,将这类信息写入 Cluster日志。
此外,可以有任意数目的 Cluster客户端进程或应用程序。它们分为两种类型:
- 标准MySQL客户端:对于MySQL Cluster,它们与标准的(非 Cluster类)MySQL没有区别。换句话讲,能够从用PHP、Perl、C、C++、Java、Python、Ruby等编写的现有MySQL应用程序访问MySQL Cluster。
- 管理客户端:这类客户端与管理服务器相连,并提供了启动和停止节点、启动和停止消息跟踪(仅调试版本)、显示节点版本和状态、启动和停止备份等的命令。
三、开始准备
1、准备服务器
现在,我们计划建立有5个节点的MySQL CLuster体系,因此需要用到5台机器,分别做如下用途:
节点(用途) IP地址(主机名) 管理节点(MGM) 192.168.0.1(db1) SQL节点1(SQL1) 192.168.0.2(db2) SQL节点2(SQL2) 192.168.0.3(db3) 数据节点1(NDBD1) 192.168.0.4(db4) 数据节点2(NDBD2) 192.168.0.5(db5)
2、注意事项及其他
每个节点的操作系统都是Linux,下面的描述中将使用主机名,不再使用IP地址来表示。由于MySQL Cluster采用TCP/IP方式连接,并且节点之间的数据传输没有加密,因此这个体系最好只在单独的子网中运行,并且考虑到传输的速率,强烈建议不要跨越公网使用这个体系。所需的MySQL软件请事先在 http://dev.mysql.com/downloads 下载。
实际上整个体系可以在一个单独的实体计算机上运行成功,当然了,必须设定不同的目录以及端口等,只能作为测试时使用。
四、开始安装
1、假定条件
在每个节点计算机上都采用 nobody 用户来运行Cluster,因此执行如下命令添加相关用户(如果已经存在则略过,且用root用户执行):
root# /usr/sbin/groupadd nobody root# /usr/sbin/useradd nobody -g nobody
假设已经下载了mysql可直接使用的二进制安装包,且放在 /tmp 下了。
2、SQL节点和存储节点(NDB节点)安装(即4个机器重复执行以下步骤)
root# cd /tmp/ root# tar zxf mysql-max-5.0.24-linux-i686.tar.gz root# mv mysql-max-5.0.24-linux-i686 /usr/local/mysql/ root# cd /usr/local/mysql/ root# ./configure --prefix=/usr/local/mysql root# ./scripts/mysql_install_db root# chown -R nobody:nobody /usr/local/mysql/
3、配置SQL节点
root# vi /usr/local/mysql/my.cnf
然后输入如下内容:
[mysqld] basedir = /usr/local/mysql/ datadir = /usr/local/mysql/data user = nobody port = 3306 socket = /tmp/mysql.sock ndbcluster ndb-connectstring=db1 [MYSQL_CLUSTER] ndb-connectstring=db1
4、配置存储节点(NDB节点)
root# vi /usr/local/mysql/my.cnf
然后输入如下内容:
[mysqld] ndbcluster ndb-connectstring=db1 [MYSQL_CLUSTER] ndb-connectstring=db1
5、安装管理节点
root# cd /tmp/ root# tar zxf mysql-max-5.0.24-linux-i686.tar.gz root# mkdir /usr/local/mysql/ root# mkdir /usr/local/mysql/data/ root# cd mysql-max-5.0.24-linux-i686/bin/ root# cp ndb_mgm* /usr/local/mysql/ root# chown -R nobody:nobody /usr/local/mysql
6、配置管理节点
root# vi /usr/local/mysql/config.ini
然后输入如下内容:
[NDBD DEFAULT] NoOfReplicas=1 [TCP DEFAULT] portnumber=3306 #设置管理节点服务器 [NDB_MGMD] hostname=db1 #MGM上保存日志的目录 datadir=/usr/local/mysql/data/ #设置存储节点服务器(NDB节点) [NDBD] hostname=db4 datadir=/usr/local/mysql/data/ #第二个NDB节点 [NDBD] hostname=db5 datadir=/usr/local/mysql/data/ #设置SQL节点服务器 [MYSQLD] hostname=db2 #第二个SQL节点 [MYSQLD] hostname=db3
注释: Cluster管理节点的默认端口是1186,数据节点的默认端口2202。从MySQL 5.0.3开始,该限制已被放宽, Cluster能够根据空闲的端口自动地为数据节点分配端口。如果你的版本低于5.0.22,请注意这个细节。
五、启动MySQL Cluster
较为合理的启动顺序是,首先启动管理节点服务器,然后启动存储节点服务器,最后才启动SQL节点服务器:
- 在管理节点服务器上,执行以下命令启动MGM节点进程:
root# /usr/local/mysql/ndb_mgmd -f /usr/local/mysql/config.ini
必须用参数“-f”或“--config-file”告诉 ndb_mgm 配置文件所在位置,默认是在ndb_mgmd相同目录下。
- 在每台存储节点服务器上,如果是第一次启动ndbd进程的话,必须先执行以下命令:
root# /usr/local/mysql/bin/ndbd --initial
注意,仅应在首次启动ndbd时,或在备份/恢复数据或配置文件发生变化后重启ndbd时使用“--initial”参数。因为该参数会使节点删除由早期ndbd实例创建的、用于恢复的任何文件,包括用于恢复的日志文件。
如果不是第一次启动,直接运行如下命令即可:root# /usr/local/mysql/bin/ndbd
- 最后,运行以下命令启动SQL节点服务器:
root# /usr/local/mysql/bin/mysqld_safe --defaults-file=/usr/local/mysql/my.cnf &
如果一切顺利,也就是启动过程中没有任何错误信息出现,那么就在管理节点服务器上运行如下命令:
root# /usr/local/mysql/ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> SHOW Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.4 (Version: 5.0.22, Nodegroup: 0, Master) id=3 @192.168.0.5 (Version: 5.0.22, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.1 (Version: 5.0.22) [mysqld(SQL)] 1 node(s) id=2 (Version: 5.0.22) id=3 (Version: 5.0.22)
具体的输出内容可能会略有不同,这取决于你所使用的MySQL版本。
注意:如果你正在使用较早的MySQL版本,你或许会看到引用为‘[mysqld(API)]’的SQL节点。这是一种早期的用法,现已放弃。
现在,应能在MySQL Cluster中处理数据库,表和数据。
六、创建数据库表
与没有使用 Cluster的MySQL相比,在MySQL Cluster内操作数据的方式没有太大的区别。执行这类操作时应记住两点:
- 表必须用ENGINE=NDB或ENGINE=NDBCLUSTER选项创建,或用ALTER TABLE选项更改,以使用NDB Cluster存储引擎在 Cluster内复制它们。如果使用mysqldump的输出从已有数据库导入表,可在文本编辑器中打开SQL脚本,并将该选项添加到任何表创建语句,或用这类选项之一替换任何已有的ENGINE(或TYPE)选项。
- 另外还请记住,每个NDB表必须有一个主键。如果在创建表时用户未定义主键,NDB Cluster存储引擎将自动生成隐含的主键。(注释:该隐含 键也将占用空间,就像任何其他的表索引一样。由于没有足够的内存来容纳这些自动创建的键,出现问题并不罕见)。
下面是一个例子:
在db2上,创建数据表,插入数据:
[db2~]root# mysql -uroot test [db2~]mysql> create table city( [db2~]mysql> id mediumint unsigned not null auto_increment primary key, [db2~]mysql> name varchar(20) not null default '' [db2~]mysql> ) engine = ndbcluster default charset utf8; [db2~]mysql> insert into city values(1, 'city1'); [db2~]mysql> insert into city values(2, 'city2');
在db3上,查询数据:
[db3~]root# mysql -uroot test [db2~]mysql> select * from city; +-----------+ |id | name | +-----------+ |1 | city1 | +-----------+ |2 | city2 | +-----------+
七、安全关闭
要想关闭 Cluster,可在MGM节点所在的机器上,在Shell中简单地输入下述命令:
[db1~]root# /usr/local/mysql/ndb_mgm -e shutdown
运行以下命令关闭SQL节点的mysqld服务:
[db2~]root# /usr/local/mysql/bin/mysqladmin -uroot shutdown
八、其他
关于MySQL Cluster更多详细的资料以及备份等请参见MySQL手册的“MySQL Cluster(MySQL 集群)”章节。
参考资料:《MySQL 5.1 中文手册》
评论
游客 (未验证)
周四, 2006/09/07 - 10:08
Permalink
好文章!good.
好文章!good.
Jeff (未验证)
周六, 2007/04/14 - 21:38
Permalink
非常不错的文章,希
非常不错的文章,希望作者继续努力,创作出更好,更有价值的作品,大力支持
dragonchencm (未验证)
周二, 2007/07/17 - 21:14
Permalink
very good!thanks for you
very good!thanks for you share!!!
游客 (未验证)
周日, 2006/10/01 - 15:07
Permalink
大部分内容都出自
大部分内容都出自mysql中文手册,何必再写成文章呢
yejr
周日, 2006/10/01 - 23:43
Permalink
手册上确实都能找
手册上确实都能找得到,但是真正去看手册的有多少人呢?本文只是快速总结而已,并不是创新。
欢迎来到MySQL中文网: http://imysql.cn
给你的祝福,要让你招架不住!
游客 (未验证)
周一, 2010/03/01 - 13:35
Permalink
小荣的文章越来越有
小荣的文章越来越有深度了
笑容 (未验证)
周五, 2006/12/29 - 01:14
Permalink
NDB节点和SQL节点放一
NDB节点和SQL节点放一个电脑上 怎么样?
yejr
周五, 2006/12/29 - 14:21
Permalink
当然可以,但是这样不
当然可以,但是这样不好啊,不利于提高可靠性,这就背离了集群的初衷,不过如果只是为了试验就无所谓了.
MySQL中文网: http://imysql.cn
Google MySQL中文用户群:http://groups.google.com/group/imysql
给你的祝福,要让你招架不住!
ghbspecial
周四, 2007/05/31 - 18:56
Permalink
to
to 叶老师:
看了您的文章,有一些凝问,请点解一下,谢谢。
按照这个文档的mysql集群,用户在连接或请求mysql连接的应该是连接那两台sql,db1和db2,那么这样的集群相当于有两个IP地址的分流负载。而很多时候是需要连接到一个IP,之后通过IP这个进行集群比如LVS,而对于这种集也没有什么机制可以访问一个,之后被调度到多个。
oracle RAC高性能集群,对外提供一个IP,之后在内部把请求分流到多个RAC的节点上面,以达到负载的目的,后端存储使用集群文件系统,以达到并发写的要求。
yejr
周四, 2007/05/31 - 19:34
Permalink
1. 只用一个sql节点 2.
1. 只用一个sql节点
2. 用lvs就可以了啊,不过我没做过 :)
MySQL方案、培训、支持
给你的祝福,要让你招架不住!
ghbspecial
周五, 2007/06/01 - 09:05
Permalink
to
to yejr
您说:1.只用一个sql节点
这点不是很明白,看文档中,有两个sql节点,您的意思是,所以请求连接到其中一个sql节点就可以了,就能达到负载的作用,另一个sql节点如何发挥的作用。
yejr
周五, 2007/06/01 - 11:16
Permalink
我的意思是只启用一
我的意思是只启用一个sql节点,另外,只用一个sql节点的话自然无法达到负载均衡作用。
MySQL方案、培训、支持
给你的祝福,要让你招架不住!
游客 (未验证)
周二, 2007/08/21 - 16:01
Permalink
我的问题和1F的一样,
我的问题和1F的一样,目前正在学习mysql的cluster,现在已经配置好了,但现在还是搞不懂提供哪一个mysql节点给应用程序作接口.如果提供的mysql节点down了,程序该如何自动接管到其他mysql节点呢?
欢迎各位大虾指教qq:644585659
yejr
周二, 2007/08/21 - 21:34
Permalink
采用多个sql节点就可
采用多个sql节点就可以了
MySQL方案、培训、支持
MySQL 用户组
aaron (未验证)
周日, 2007/12/09 - 23:54
Permalink
有两个基础问题
有两个基础问题 还没搞清楚。
1。文中db1管理而实际的表文件是存储在db4 db5上对吗?
2。“NDB” 是一种“内存中”的存储引擎 ,那我如果在 db2上 创建的了一个表 是直接写到 db4 db5的硬盘的表文件里,还是写到内存里?
yejr
周一, 2007/12/10 - 07:04
Permalink
1. 是的 2.
1. 是的
2. 取决于你创建的表类型,先好好理解一下NDB表和其他表类型的区别吧
MySQL方案、培训、支持
MySQL 用户组
aaron (未验证)
周一, 2007/12/10 - 11:56
Permalink
首先谢谢您的认真负
首先谢谢您的认真负责以及热心
如果我 用ENGINE=NDB或ENGINE=NDBCLUSTER选项创建
那么 在 db2上 创建的了一个表 是直接写到 db4 db5的硬盘的表文件里,还是写到内存里?
yejr
周一, 2007/12/10 - 12:43
Permalink
建议你仔细读一下MySQL
建议你仔细读一下MySQL手册中关于cluster这章吧
MySQL方案、培训、支持
MySQL 用户组
游客 (未验证)
周一, 2008/01/14 - 15:01
Permalink
想请教下叶老师,数据
想请教下叶老师,数据节点怎么样配置内存?是否放数据节点的那部机的全部内存都被集群用还是配置哪个文件来限制集群用多少内存?谢谢
游客 (未验证)
周日, 2008/07/20 - 04:50
Permalink
問題: SQL节点1(SQL1) 1
問題:
SQL节点1(SQL1) 192.168.0.2(db2)
SQL节点2(SQL2) 192.168.0.3(db3)
1. 是否可作成同一IP基於OpenSUSE的HA技術,即以上兩台電腦安裝HA,然後通過HA服務建立好單一IP地址做高可用性.
2. 若問題1.不行,分開IP地址訪問時如果同一時間訪問,即db2改寫及db3立即讀會否出現不同步或鎖定問題, 是否可直接以Transaction理解.
yejr
周日, 2008/07/20 - 08:17
Permalink
1 是可以的。 2
1 是可以的。
2 应该是不行的,连接已中断,事务自然也中断,mysql还不支持分布式事务
MySQL方案、培训、支持
游客 (未验证)
周日, 2008/07/20 - 11:33
Permalink
2.
2. 若問題1.不行,分開IP地址訪問時如果同一時間訪問,即db2改寫及db3立即讀會否出現不同步或鎖定問題, 是否可直接以Transaction理解.
2.的問題是:
我不做HA方案於db2及db3,那客戶端程式SQL字串訪問時是要用分別是db2或db3,如果那時候是:
a) 客戶端1通過db2連接字串,運行Storge內的Data,目的是改資料.
UPDATE SET TABLE WHERE XXXXX
b) 客戶端2通過db3連接字串,運行Storge內的Data,目的是查資料.
SELECT TABLE ALL XXXXXX
如同一張表內的某一行讀或寫同時會否出現什麼問題? (我目前理解所有Data是在Storge內的)
yejr
周日, 2008/07/20 - 11:39
Permalink
明白你的意思了,ndb
明白你的意思了,ndb引擎和innodb类似,都支持transaction,当然不会有问题。sql节点本身不存储任何data,只是一个接口而已。data存储在上面提到的data节点。
MySQL方案、培训、支持
macaujohn2000
周日, 2008/07/20 - 14:49
Permalink
1.
1. 另外想問多個問題,如果Storge內其中某一電腦死了,整體會怎麼樣,是否自動換?
2. 還有,如果把Storge內死機的電腦修復後,要設什麼參數才能搬回去做Cluster呢,步驟是怎麼樣?
yejr
周日, 2008/07/20 - 16:48
Permalink
具体实现细节看手册
具体实现细节看手册描述吧,这东西不是我一言两语能描述清楚的
MySQL方案、培训、支持
macaujohn2000
周日, 2008/07/20 - 15:50
Permalink
节点(用途) IP地址(主
节点(用途) IP地址(主机名)
管理节点(MGM) 192.168.0.1(db1)
SQL节点1(SQL1) 192.168.0.2(db2)
SQL节点2(SQL2) 192.168.0.3(db3)
数据节点1(NDBD1) 192.168.0.4(db4)
数据节点2(NDBD2) 192.168.0.4(db5)
想問問為何: 数据节点2(NDBD2) 192.168.0.4(db5) 不是 192.168.0.5 ? 為何可重複IP的 ?
yejr
周日, 2008/07/20 - 16:47
Permalink
修改了,纯属笔误
修改了,纯属笔误 :)
MySQL方案、培训、支持
macaujohn2000
周日, 2008/07/20 - 17:22
Permalink
還有在官網找不到mysql
還有在官網找不到mysql-max的檔案下載,是否已經變更成另外檔名 ??
mysql-cluster-gpl-6.2.15-linux-i686-glibc23.tar.gz
yejr
周日, 2008/07/20 - 18:12
Permalink
老兄,这是06年的文
老兄,这是06年的文章,你不觉得应该看最新的手册吗?
http://dev.mysql.com/downloads/cluster/
MySQL方案、培训、支持
macaujohn2000
周日, 2008/07/20 - 20:30
Permalink
那是否所有電腦都要
那是否所有電腦都要安MySQL Client原程序?? 不是指Cluster程序 .....
或只是安Cluster就可了嗎 ?
蚂蚁 (未验证)
周二, 2010/07/20 - 17:08
Permalink
LZ你好,按你方法做之
LZ你好,按你方法做之后成功了。
ndb_mgm> show
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.3.237 (mysql-5.1.44 ndb-7.1.3, Nodegroup: 0, Master)
id=3 @192.168.3.238 (mysql-5.1.44 ndb-7.1.3, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.3.240 (mysql-5.1.44 ndb-7.1.3)
[mysqld(API)] 1 node(s)
id=4 @192.168.3.239 (mysql-5.1.44 ndb-7.1.3)
但是有个问题,在哪个节点建表、建库,都不能在另一个节点数据同步。。。。求救。。。
游客 (未验证)
周五, 2013/07/19 - 16:17
Permalink
管理节点可以有多个吗?
管理节点可以有多个吗?
yejr
周日, 2013/07/21 - 23:47
Permalink
目前的新版本是可以的,主管理节点当掉后,可以使用备用节点
目前的新版本是可以的,主管理节点当掉后,可以使用备用节点
woshi_bobo (未验证)
周二, 2014/04/01 - 16:38
Permalink
你好!我想问你一下 ,如果有多个SQL节点,比如SQL1
你好!我想问你一下 ,如果有多个SQL节点,比如SQL1:192.168.100.1、SQL2:192.168.2、SQL3:192.168.100.3 那么java程序连接数据库的字符串该怎么些?是把所有的节点都连接上还是mysql cluster能提供一个统一的管理的东西呢??如果是都写上,那么以后增加删除节点的话 就要经常改动代码了呀。。。困扰我好几天了,希望你能给我解答下!谢谢!!!
yejr
周一, 2014/11/03 - 14:49
Permalink
在NDB Cluster集群中
在NDB Cluster集群中,多个SQL节点的作用是完全一样的,你可以配置为其中任何一个节点的IP,也可以在前端封装一个LVS或者haproxy之类的,对外用VIP(虚拟IP)提供服务。
游客 (未验证)
周四, 2014/07/31 - 11:40
Permalink
想问下 如果 我的数据节点(ndbd)有3台机器
想问下 如果 我的数据节点(ndbd)有3台机器(每台200g空间)。 我在sql节点上创建了一个表,并且存入数据,我发现我每个数据节点都存在。证明是3份,如果我在加7台机器到数据节点(ndbd)(每台200g空间),是不是我在创建一个表就是10份呢。也就是说我虽然有10台200G的机器,我最多能存200G的数据在集群里。能不能数据库里的数据分散的存在在这十台机器中。每个机器存一部分数据, 可以吗。
yejr
周一, 2014/11/03 - 14:37
Permalink
NoOfReplicas
NoOfReplicas 参数决定了数据最终会被冗余复制多少份以防丢失。
一份数据不能完全平均分不到各个节点,在NDB Cluster的应用场景下,最好至少要有2份冗余,一般建议3份,甚至更多。