只需三步,即可完成一个本地化DeepSeek体验环境。
在学习完 给小白3天学会DeepSeek的锦囊 后,有一定工程基础的同学可以在本地部署一个DeepSeek测试环境,更近距离体验DeepSeek。
部署DeepSeek环境无需专业的GPU显卡,本文的测试环境就是基于普通PC机完成,其配置为 两核Intel i7 CPU、64G内存、SSD盘,已安装Linux系统(在Windows环境下也能体验)。
第1步,下载安装ollama
Ollama 是一个开源的 AI 平台,由 Meta 开发,允许用户运行、自定义并训练各种语言模型。它支持多种预训练模型(如 GPT-4, Claude, DeepSeek 等),并提供友好的用户界面和工具链,适用于开
发者和研究者。官网地址:https://ollama.com。
如果服务器在墙外,则可以直接执行下面的命令一键完成安装
$ wget -c https://ollama.com/install.sh | sh
如果是在墙内,则需要先手动下载二进制安装包
$ wget -c https://ollama.com/download/ollama-linux-amd64.tgz
如果上述链接还是无法下载,可以下载我分享到百度云盘上的资源 https://pan.baidu.com/s/1a4DVIqag8FJdUtLwfxmotg?pwd=deep。
上传到Linux服务器上,然后手动完成安装部署。
先创建相关用户
$ useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
$ usermod -a -G render ollama
$ usermod -a -G video ollama
$ usermod -a -G ollama $(whoami)
编辑ollama服务配置文件 /etc/systemd/system/ollama.service,参考下面的内容
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/.pyenv/shims:/root/.pyenv/bin:/root/perl5/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/mysql-latest/bin"
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target
重新加载并重启ollama服务
$ systemctl daemon-reload && systemctl restart ollama
查看ollama服务运行状态
$ systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2025-02-06 15:32:58 CST; 11min ago
Main PID: 13451 (ollama)
Tasks: 15
Memory: 2.3G
CGroup: /system.slice/ollama.service
├─13451 /usr/local/bin/ollama serve
└─19845 /usr/local/lib/ollama/runners/cpu_avx2/ollama_llama_server runner --model /usr/share/ollama/.ollama/models/blobs/sha256-aabd4debf0c8f0
...
查看端口监听状态
ss -anlp|grep 11434
tcp LISTEN 0 128 [::]:11434 [::]:* users:(("ollama",pid=13451,fd=3))
在浏览器中访问地址 http://192.168.0.123:11434 (192.168.0.123是我的测试机IP地址),浏览器中如果出现下面的提示即为成功
Ollama is running
第1步完成。
第2步,部署DeepSeek R1模型
在ollama官网首页上,就有DeepSeek-R1模型的入口,点击进入。
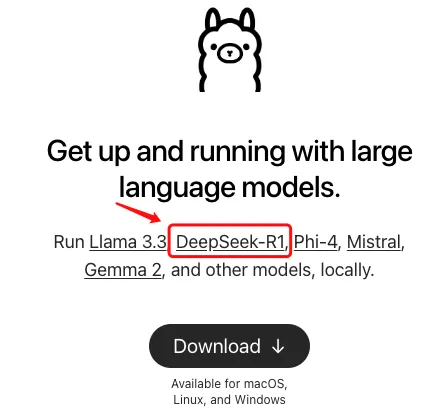
默认的版本是7b,不同版本对应的体积大小不同,体积越大模型越精细化,运行它们所需要的内存也分别不同。各版本所需内存大约如下表所示,可根据自己测试机配置选择合适的版本
| 版本 | 所需内存预估 |
|---|---|
| 1.5b | 1.5G |
| 7b | 5G |
| 8b | 6G |
| 14b | 20G |
在这里我选择了8b版本。
$ ollama run deepseek-r1:8b
然后就耐心等待吧,如果中间失败了也没关系,ollama支持断点续传,再次执行即可。最终运行成功后大概像下面这样
...
pulling manifest
pulling aabd4debf0c8... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████▏ 387 B
...
verifying sha256 digest
writing manifest
success
>>> 请你简单介绍下DeepSeek,谢谢
<think>
嗯,用户让我介绍一下DeepSeek。首先,我得确定DeepSeek是什么,是AI公司还是公司的名称?可能是一个科技公司或者一个专注特定领域的企业。
...
</think>
DeepSeek是一家专注于人工智能技术的研究公司或企业。它致力于开发智能化解决方案,涵盖多个领域如语音识别、图像处理、数据分析等。DeepSeek的核心目标是为复杂问
题提供高效智能支持,帮助用户提升效率并应对挑战。
...
>>> /bye
第2步,也部署成功了,并且已经能回答一些基本问题,可以根据前文 给小白3天学会DeepSeek的锦囊 提供的方法试着玩一玩。
向DeepSeek提问时,能看到此时CPU在满负荷工作中
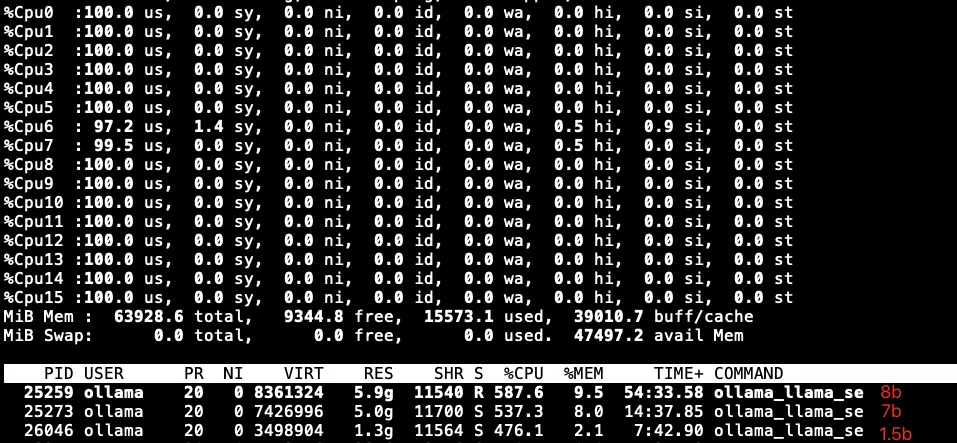
执行 ollama list 列出当前已下载的模型列表
$ ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 30 hours ago
deepseek-r1:8b 28f8fd6cdc67 4.9 GB 30 hours ago
deepseek-r1:7b 0a8c26691023 4.7 GB 30 hours ago
第3步,部署可视化交互界面
接下来可以从Chatbox、open-webui、Dify中选择一个可视化交互界面方案。
-
Chatbox是一个对话工具,可以导入各种大模型平台的API,或者本地部署模型的API也都是可以的,官网地址:https://www.chatboxai.app/zh。
-
Open WebUI 是一个功能强大的开源 AI 界面,支持多种 AI 模型的接入,包括 Ollama、OpenAI API 等。本教程将指导你如何在 Open WebUI 中配置和使用 Deepseek API,让你能够快速搭建自己的 AI 助手系统。官网地址:https://docs.openwebui.com。
-
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。官网地址: https://docs.dify.ai/zh-hans。
我选择了Open WebUI,因为可以用Docker来完成部署,更方便快捷。
在开始之前,先修改Docker配置文件 /etc/docker/daemon.json,增加国内的镜像源地址(不得不吐槽下,很多资源被墙了,经常要各种折腾,费时费力)
{
"registry-mirrors" : [ "https://docker.nju.edu.cn", "https://ghcr.nju.edu.cn", "https://gcr.nju.edu.cn", "https://ngc.nju.edu.cn", "https://quay.nju.edu.cn"],
"insecure-registries": [ "https://docker.nju.edu.cn", "https://ghcr.nju.edu.cn", "https://gcr.nju.edu.cn", "https://ngc.nju.edu.cn", "https://quay.nju.edu.cn"],
"experimental": true
}
重启Docker使之生效
$ systemctl daemon-reload && systemctl restart docker
如果是podman环境,则修改配置文件 /etc/containers/registries.conf,同样地,增加国内镜像资源:
unqualified-search-registries = ["docker.nju.edu.cn", "ghcr.nju.edu.cn", "gcr.nju.edu.cn", "ngc.nju.edu.cn", "quay.nju.edu.cn"]
运行下面的命令,利用Docker一键完成
$ docker run -itd -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.0.123:11434 -v open-webui:/app/backend/data --name ollama-open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
...
$ docker ps | grep -i webui
e5ec34b719eb ghcr.nju.edu.cn/open-webui/open-webui:main bash start.sh 4 seconds ago Up 4 seconds ago 0.0.0.0:3000->8080/tcp ollama-open-webui
容器创建成功后,需要先进行初始化工作,等待一会儿再在浏览器中输入地址 http://192.168.0.123:3000 访问,如果可以看到下面的内容就表示成功

第一次打开时需要先创建管理员账户,然后登入,就可以看到下面这样的界面,这就可以在浏览器和DeepSeek进行对话
接下来,点击左上角 “工作空间” => “知识库”,创建我们自己的知识库。可以选择上传单个文件,也可以将整个本地知识库目录都上传,也可以在线添加文本资料。


我体验了几次问答,如果是一些简单的常识问题,本地的DeepSeek-R1 8b版本基本上还能应付得来,如果问的是一些关于MySQL/GreatSQL专业的问题,它就开始有点胡说八道了。可见如果想要得到更好的效果和更专业的回答内容,还需要用更好的服务器配置并选择更高版本的DeepSeek模型。

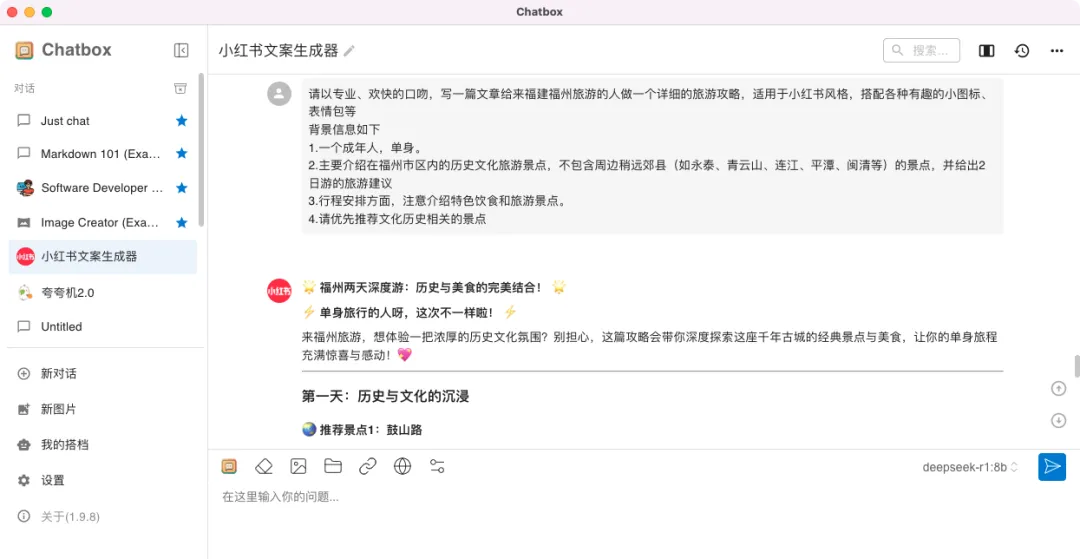
写到这里,我也尝试了用Chatbox来接入本地的DeepSeek,它还搭载了很多好玩的AI组件,非常方便实用
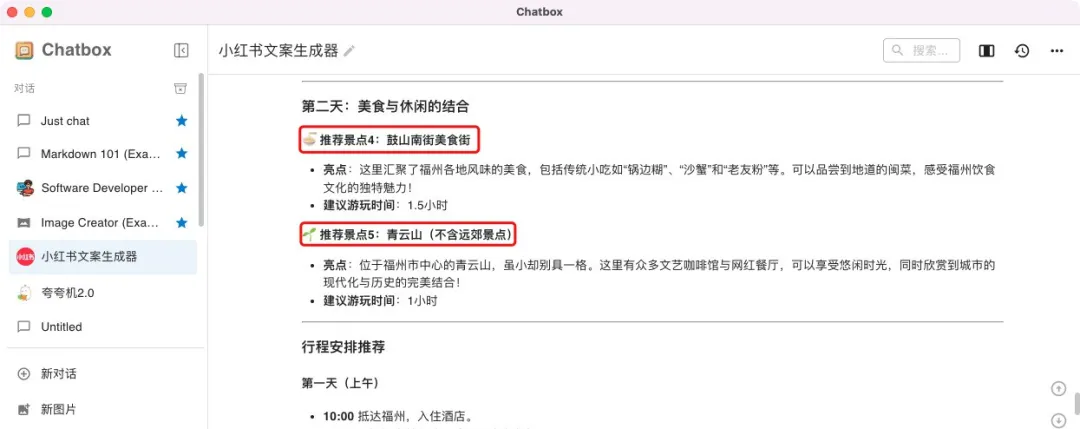
让它帮忙写一个福建福州市区轻松文旅游攻略的文案试试看,在它的回答中仍有挺多待改进的地方,例如我要求不包含永泰等郊县,但还是推荐了青云山景点
这次先写到这里。在最后,分享一个南京大学的Docker镜像资源,可以方便的在墙内拉取到很多Docker镜像,详见:https://sci.nju.edu.cn/9e/05/c30384a564741/page.htm。
